拖动LOGO到书签栏,立即收藏悟空网址导航
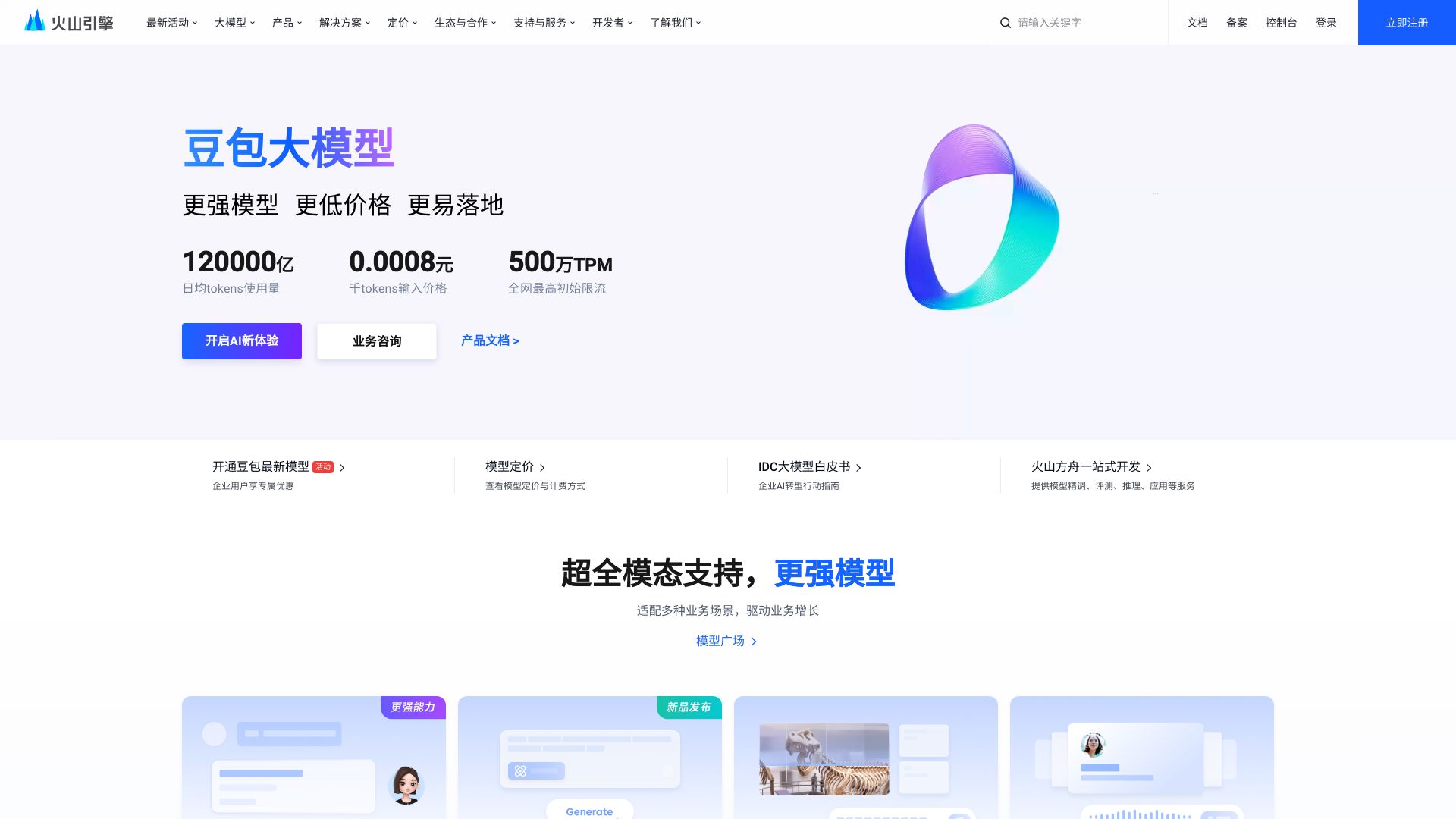
豆包大模型是字节跳动推出的AI大模型家族,旨在通过先进的人工智能技术赋能各个领域。这个家族包含多个强大的模型,包括视频生成、语音视觉和通用语言模型等,旨在满足用户的多样化需求。
首先,豆包大模型在视频生成领域展现了卓越的能力。利用AI技术,该模型可以自动生成高质量的视频内容,从而大幅降低了视频制作的门槛。无论是短视频创作者还是大型传媒公司,都可以通过这一技术生成符合其需求的视频内容。这不仅提高了内容生产效率,也为创意表达提供了更多可能。
在语音和视觉方面,豆包大模型同样表现出色。通过结合语音识别与视觉处理技术,该模型可以实现多模态的智能交互。这意味着用户可以通过自然语言与设备进行对话,同时设备也能通过视觉感知环境,做出相应的反馈。这种能力在智能家居、自动驾驶、医疗辅助等领域都有着广泛的应用前景。
此外,豆包大模型还包括了强大的通用语言模型。这一模型可以进行自然语言理解、生成和翻译,支持多种语言与方言的处理。这使得它在文本分析、内容生成、客户服务等领域都有着广泛的应用。通过不断地学习和优化,通用语言模型能够理解并生成更为流畅、自然的文本内容,从而提升用户体验。
豆包大模型的推出不仅展示了字节跳动在AI技术领域的创新能力,也为各行业提供了丰富的应用场景。无论是媒体、教育、娱乐,还是医疗、金融、制造业,豆包大模型都能提供定制化的解决方案。通过与行业专家的合作,字节跳动不断优化模型性能,推出更加贴合行业需求的AI产品。
在技术实现上,豆包大模型依托于字节跳动强大的计算能力和海量的数据资源。通过不断的训练与迭代,这些模型得以持续提升性能,并为用户提供更为可靠和高效的服务。字节跳动还为开发者提供了丰富的API接口和开发工具,帮助他们更好地将AI技术应用到实际项目中。
综上所述,豆包大模型是一个功能强大且多样化的AI大模型家族,旨在通过提升生产力与创造力,为用户提供更为智能的解决方案。随着技术的不断进步与应用领域的扩展,豆包大模型将继续引领AI技术的发展,助力各行业实现数字化转型。